Arthur Zucker
October 18, 2021
Reinforcement learning, lesson 2
This post sums up the content of the lesson n°2 of RL on dynamic programming
Solving the infinite-Horizon discounted MDPs
The problem we have to solve is the following : $$ \begin{align*} \max {\pi} V^{\pi}\left(s{0}\right)= & \ = & \max {\pi} \mathbb{E}\left[r\left(s{0}, d_{0}\left(a_{0} \mid s_{0}\right)\right)+\gamma r\left(s_{1}, d_{1}\left(a_{1} \mid s_{0}, s_{1}\right)\right)+\gamma^{2} r\left(s_{2}, d_{2}\left(a_{2} \mid s_{0}, s_{1}, s_{2}\right)\right)+\ldots\right] \ =&\mathbb{E}\left[\sum_{t=0}^{\infty} \gamma^{t} r\left(s_{t}, a_{t}\right) \mid a_{t} \sim d_{t}\left(\cdot \mid h_{t}\right)\right] \end{align*} $$
Reducing the search space :
History based to markov decision
Theorem (Bertsekas [2007])
Consider an MDP with $|A|<\infty$ and an initial distribution $\beta$ over states such that $|{s \in S: \beta(s)>0}|<\infty .$ For any policy $\pi$, let $$ p_{t}^{\pi}(s, a)=\mathbb{P}\left[S_{t}=s, A_{t}=a\right] ; \quad p_{t}^{\pi}(s)=\mathbb{P}\left[S_{t}=s\right] $$ Then for any history-based policy $\pi$ there exists a Markov policy $\bar{\pi}$ such that $$ p_{t}^{\bar{\pi}}(s, a)=p_{t}^{\pi}(s, a) ; \quad p_{t}^{\bar{\pi}}(s)=p_{t}^{\pi}(s) $$ for any $s \in S, a \in A$ and $t \in \mathbb{N}^{+}$
Introduced the Discounted Occupancy measure but I don’t know why.
Non-stationary to stationary
Simplifying the value function
From stochastic to deterministic decision rules
Conclusion: we can now focus on stationary policies with deterministic markov decision rules.
Solving Finite-Horizon MDPs
Solving Infinite-Horizon Undiscounted MDPs
Summary
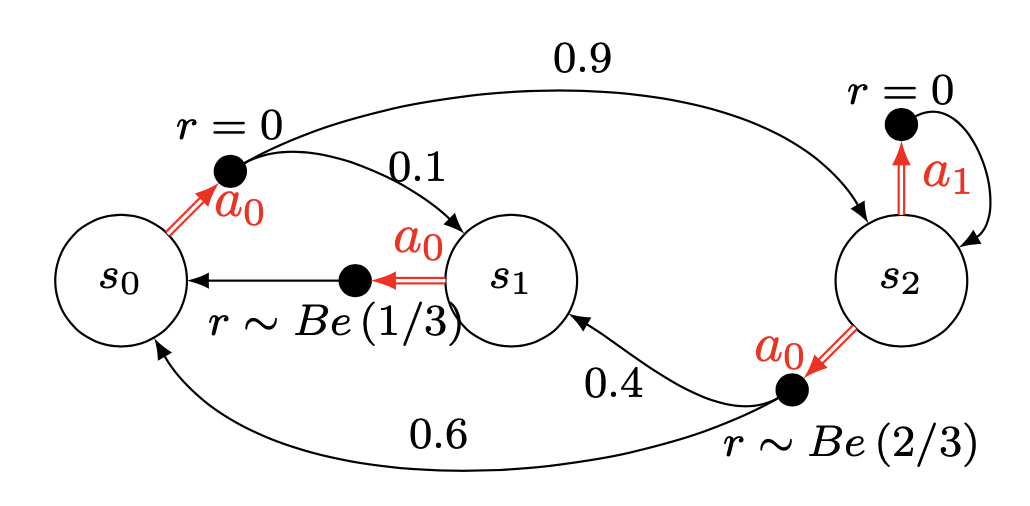
Example
Let’s apply the notions to a simple example. Let’s consider the following model :